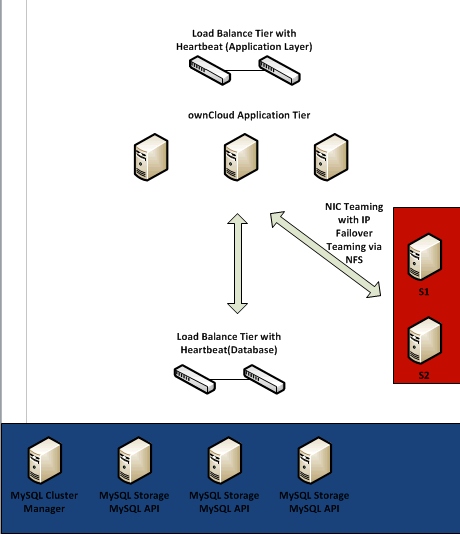
Répartition de la montée en charge sur plusieurs serveurs¶
Ce document couvre la référence d’architecture pour la montée en charge d’ownCloud pour une mise en œuvre sur un seul centre de données. Le document se concentrera sur les trois éléments essentiels :
- la couche applicative ;
- la couche base de données ;
- la couche stockage.
Pour chaque couche, le but est de pouvoir supporter la montée en charge et de fournir de la haute disponiblité tout en maintenant la qualité de service.
Couche applicative¶
Pour la couche applicative de cette référence d’architecture, nous avons utilisé Oracle Enterprise Linux comme serveurs frontaux pour héberger le code d’ownCloud. Dans cette instance, nous avons fait de httpd un domaine permissif, permettant d’opérer avec l’environnement SELinux. Dans cet exemple, nous avons aussi utilisé la structure de répertoire standard qui place le code d’ownCloud dans le répertoire racine d’Apache. Les composants suivants ont été installés sur chaque serveur applicatif :
- Apache ;
- PHP 5.4.x ;
- PHP-GD ;
- PHP-XML ;
- PHP-MYSQL ;
- PHP-CURL.
Le module PHP smbclient module ou smbclient est aussi nécessaire (voir SMB/CIFS).
Il convient aussi de mentionner que les exceptions appropriées ont été créées dans le pare-feu pour permettre le trafic d’ownCloud traffic (pour les fins de ce test, nous avons activé le chiffrement SSL sur le port 443 et les connexions non chiffrées sur le port 80).
L’étape suivante a été de générer et d’importer les certificats SSL selon le processus standard indiqué dans la documentation d’OEL.
L’étape suivante est de créer un environnement capable de supporter la montée en charge pour la couche applicative, ce qui introduit l’équilibreur de charge. Parce que les serveurs applicatifs sont ici sans état, il suffit de prendre la configuration ci-dessus et de la répliquer (une fois configurés le stockage et les connexions de base de données), et de les placer derrière l’équilibreur de charge. Ceci fournira un environnement pouvant monter en charge et à haute disponibilité. Pour cela, nous avons choisi HAProxy et l’avons configuré pour le trafic HTTPS en suivant la documentation sur ce site : http://haproxy.1wt.eu/#doc1.5
Il convient de noter que cet équilibreur de charge n’est pas obligatoire et que l’utilisation d’un équilibreur de charge commercial (comme F5) fonctionnera ici. Les serveurs HAProxy ont été configurés avec une pulsation (heartbeat) et changement d’IP en cas de défaillance.
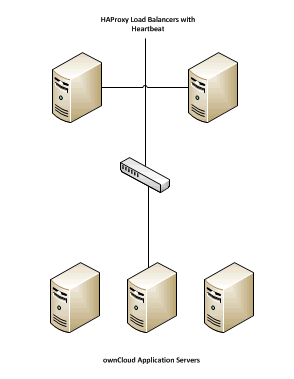
Couche base de données¶
Pour les besoins de cet exemple, nous avons choisi un cluster MySQL utilisant le moteur de stockage NDB. Le cluster a été configuré sur la base de la sur le site http://dev.mysql.com/doc/refman/5.1/en/mysql-cluster.html avec un exemple comme ceci :
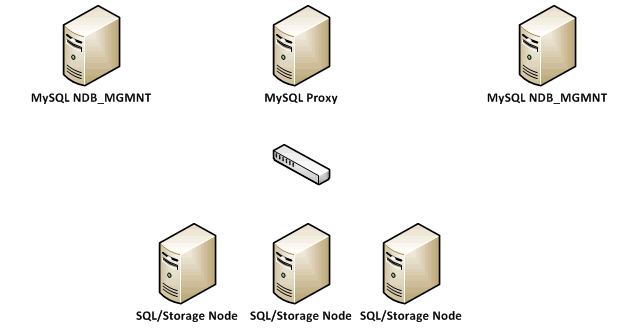
En regardant de plus près l’architecture de base de données, nous avons créé des nœuds de gestion MySQL NDB pour la redondance et nous avons configuré 3 nœuds NDB SQL/Storage pour répartir le trafic de la base de données. Tous les clients (les serveurs applicatifs ownCloud) se connecteront à la base de données via le proxy MySQL. Il est à noter que le proxy MySQL est encore en version bêta, et que l’utilisation de HAProxy ou F5 est supportée. Ici nous avons échangé le proxy MySQL pour un HAProxy bien configuré, ce qui nous donne ce qui suit :

Dans cet exemple, nous avons aussi ajouté un second HAProxy avec une pulsation pour empêcher un point unique de défaillance. Nous avons aussi mis en œuvre un bonding de cartes réseau pour répartir le trafic sur plusieurs cartes réseau physiques.
Couche stockage¶
Le stockage a été déployé en utilisant un serveur Red Hat Storage avec GlusterFS (pré-configuré dans le cadre de l’offre Red Hat Storage Server).
Les serveurs Red Hat Storage Servers ont été configurés sur la base de la documentation sur le site https://access.redhat.com/site/documentation/en-US/Red_Hat_Storage/2.0/html/Administration_Guide/Admin_Guide_Part_1.html
Pour les besoins de montée en charge et de haute disponibilité, nous avons configuré des volumes répliqués distribués avec basculement IP. Le stockage a été configuré sur un sous-réseau distinct avec un bonding de cartes réseau au niveau serveur applicatif. Nous avons choisi d’utiliser NFS pour le stockage avec basculement IP comme documenté sur https://access.redhat.com/site/documentation/en-US/Red_Hat_Storage/2.0/html/Administration_Guide/ch09s04.html
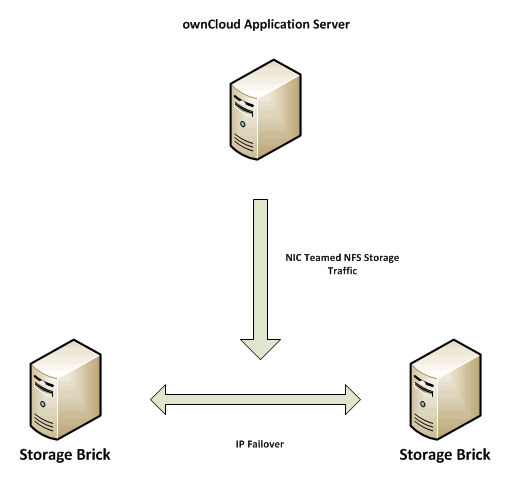
Nous avons choisi de déployer le stockage de cette façon pour la haute disponibilité et l’extensibilité du stockage tout en gérant les performances en ajoutant simplement des briques additionnelles au volume de stockage.
Il est à noter qu’il existe plusieurs options pour la configuration de stockage (comme les volumes répliqués par bandes). Une discussion sur le type de performances d’entrée/sortie requis et sur le besoin de haute disponiblité doit se faire pour comprendre et choisir la meilleure option possible.
Si nous ajoutons toutes les parties, nous avons :
- Une couche applicative qui supporte l’expansion dynamique par ajout de serveurs additionnels et fournit de la haute disponibilité à l’aide d’équilibreur de charge
- Une couche base de données qui peut être étendue par l’addition de nœuds SQL/Storage et fournit de la haute disponibilité à l’aide d’équilibreur de charge
- Une couche stockage qui peut être étendue dynamiquement et fournit de la haute disponibilité à l’aide du basculement IP